RabbitMQ
再一次学习和巩固RabbitMQ的知识,这次学习参考的视频是黑马RabbitMQ
一. MQ基础
1. 初步认识MQ
同步调用
同步调用是最基本并且最简单的一种调用方式,类 A 的 a() 调用类 B 的 b(),一直等待 b() 执行完毕,a() 继续往下走。该调用方式适用于 b() 执行时间不长的情况,因为 b() 执行时间过长或者直接阻塞的话,a() 的余下代码是无法执行下去的,这样会造成整个流程的阻塞。
对于一些业务,它们之间是有前后关系的,必须使用同步调用,如在支付服务中,在用户进行支付后,就要进行扣减余额,这里的用户字符和扣减余额就是同步调用
异步调用
异步调用是为了解决同步调用可能出现阻塞,导致整个流程卡住而产生的一种调用方式,可以创建新的线程来对这些方法或接口进行调用
如在支付服务中,在用户进行支付后,更新订单状态可以创建新的线程来执行,也就是异步调用
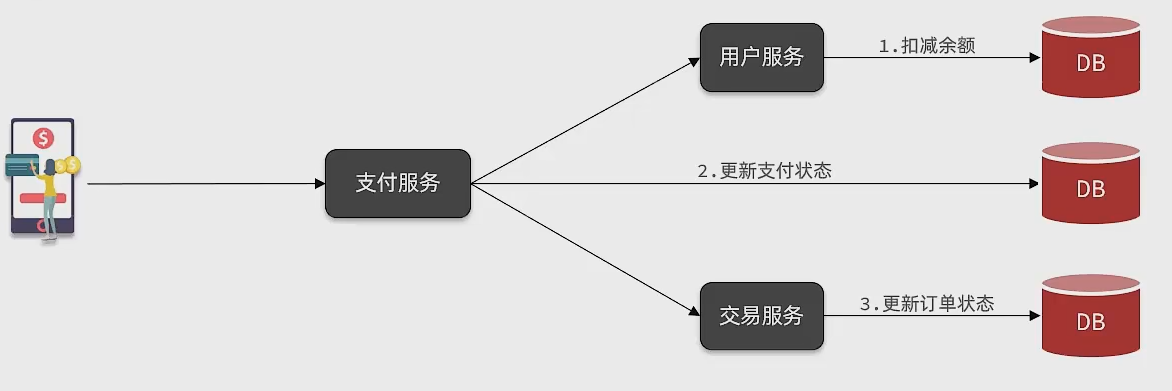
异步调用的作用
以上面的案例为例,对部分业务采取异步调用的方式,支付服务不在同步调用业务关联度低的服务,而是发送消息到Broker
采取这种方案所具备的优势:
- 解除耦合,拓展性强:将哪些与主业务隔关联性不是特别强的业务采用异步调用的方式调用,这样就不会影响到主业务,同时需要扩展相关业务时,如果与主业务关联性不强,只需要同其他业务一样,监听主业务发送的消息,通过消息代理获取到对应的消息并异步调用即可
- 无需等待,性能好:异步调用的业务所消耗的时间不会影响主业务的响应,减低了主业务的响应时间
- 故障隔离:异步调用业务之间都是相互隔离的,与主业务也是相互隔离的,发生故障后不会影响其他业务
- 缓存消息,流量削峰填谷:在流量峰值较大的时候,这些异步调用的业务会按部读取消息代理中的消息进行消费,减轻的整个业务的压力
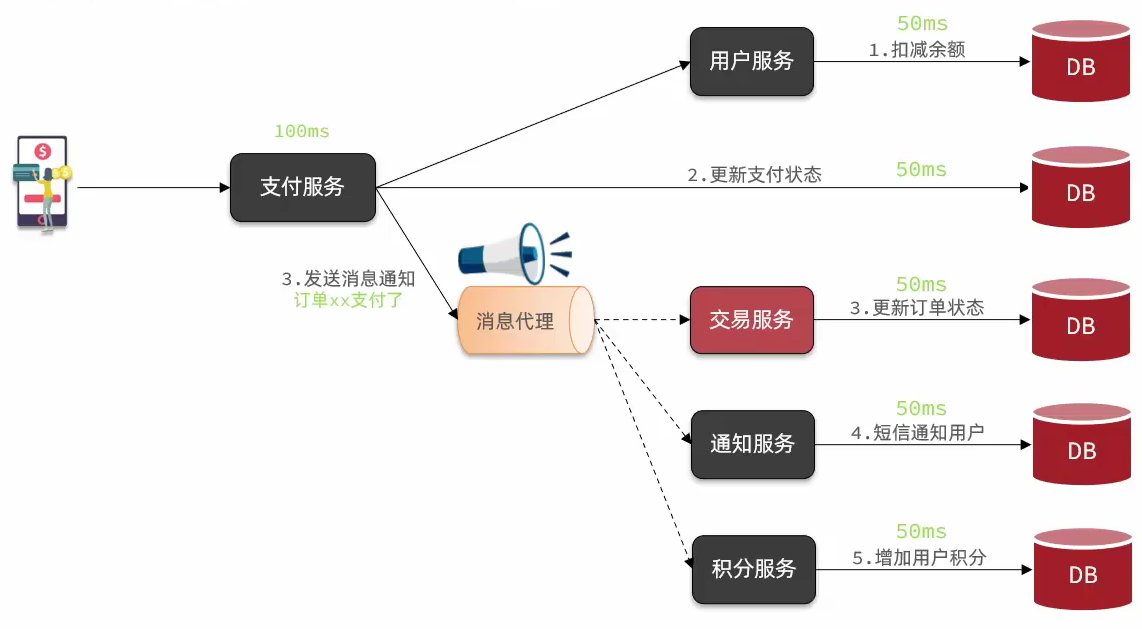
异步调用的缺点
- 不能立即得到调用结果,时效性查
- 不确定下游业务执行是否成功
- 业务安全依赖于Broker的可靠性
2. 安装
把RabbitMQ安装到Linux中
先使用docker拉取RabbitMQ镜像,我这里是直接从本地上传的
创建MQ容器
1 | |
这里的network网络要提前创建
1 | |
如果15672端口无法访问可能是服务器未关闭,或者mq的插件没有启动
启动插件需要进入到RabbitMQ的内部
1 | |
进入到rabbitmq容器内部后执行下面的命令
1 | |
然后就可以访问15672端口,并登录
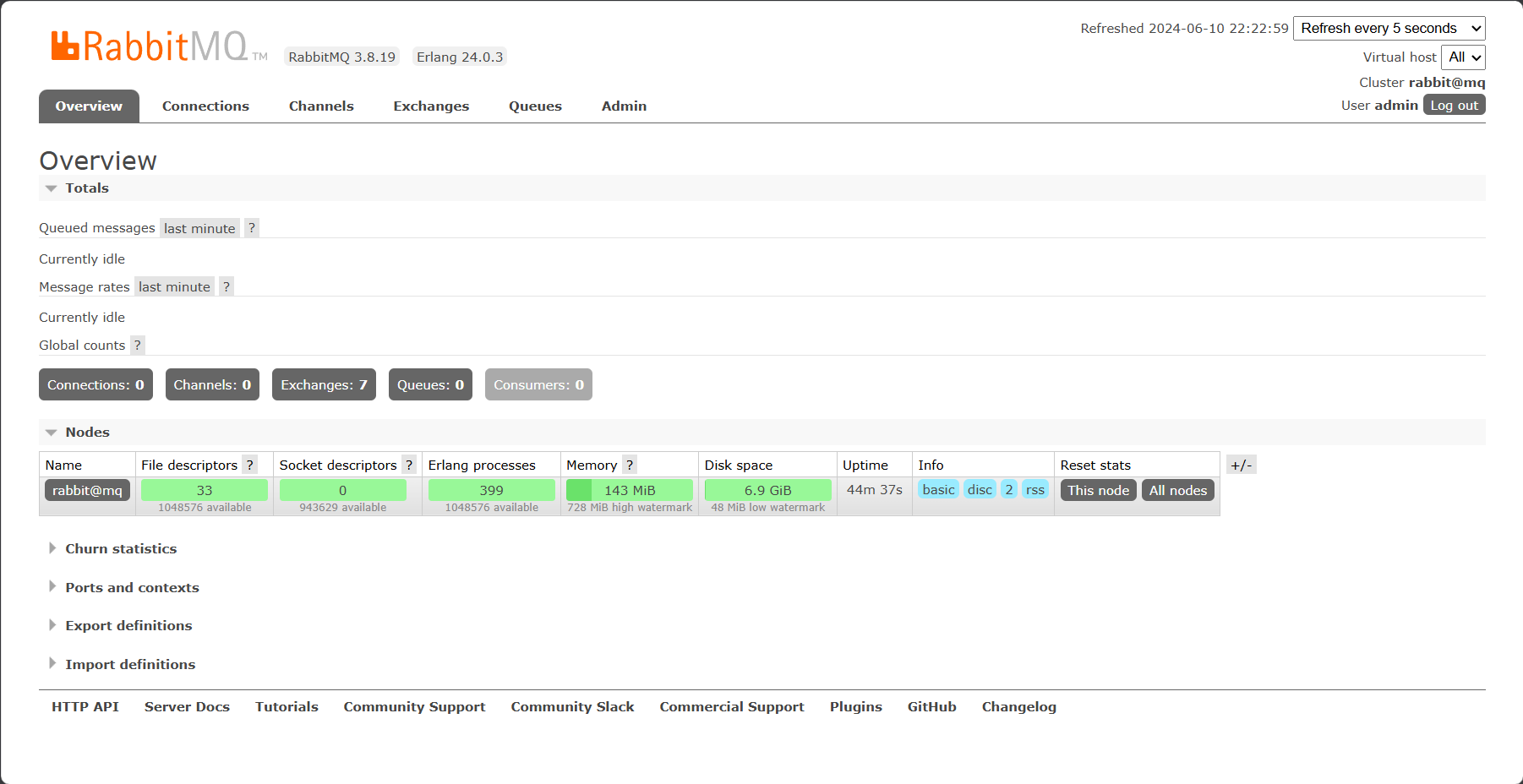
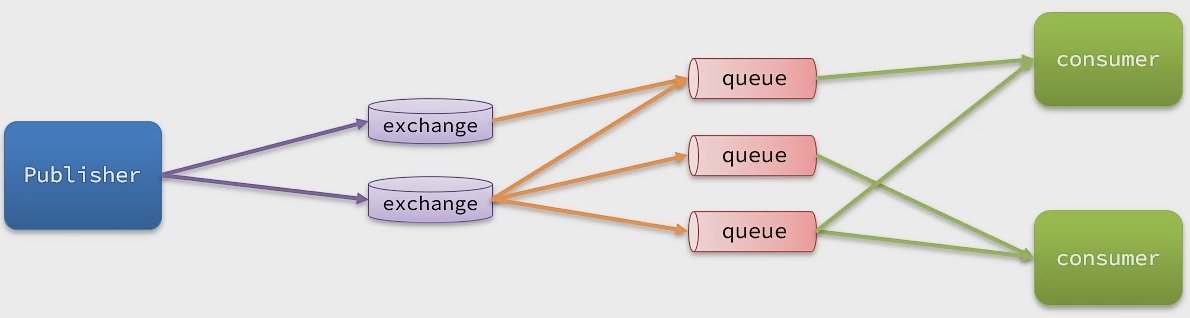
RabbitMQ的整体框架及核心概念:
- virtual-host:虚拟主机,起到数据隔离的作用
- publisher:消息发送者
- consumer:消息的消费者
- queue:队列,存储消息
- exchange:交换机,负责路由消息
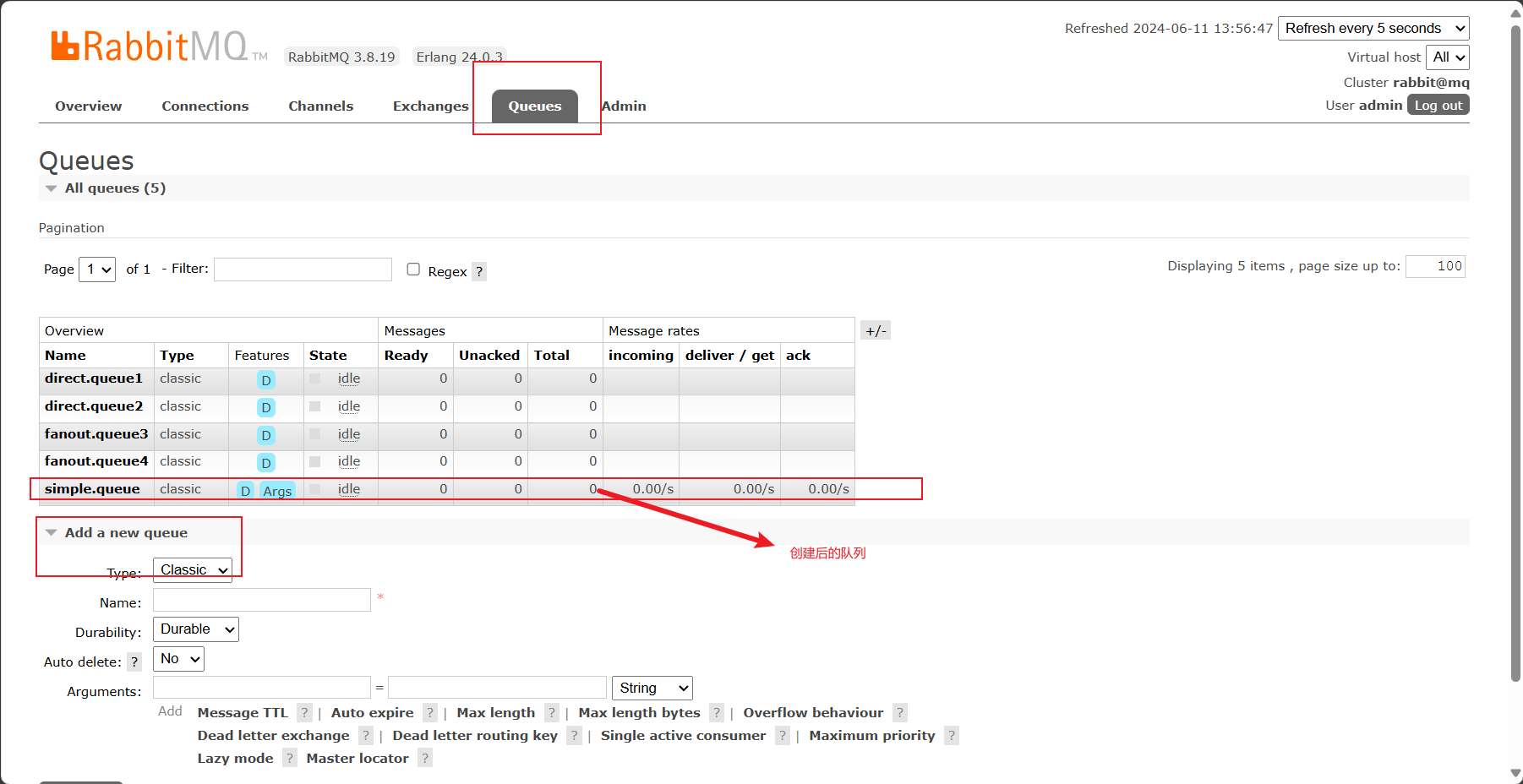
3. 快速入门
先在Web端创建一个队列
打开idea并创建项目,导入依赖,这里的快速入门使用Spring AMQP来演示
1 | |
创建消费者和生产者两个模块
生产者
在测试类中写入信息,先编写配置文件
1 | |
在编写测试类
1 | |
运行该测试方法后,可以在Web端看见队列simple.queue存在一条未消费的消息
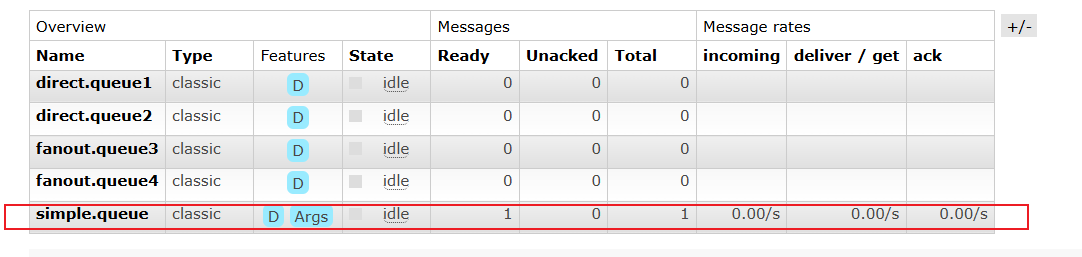
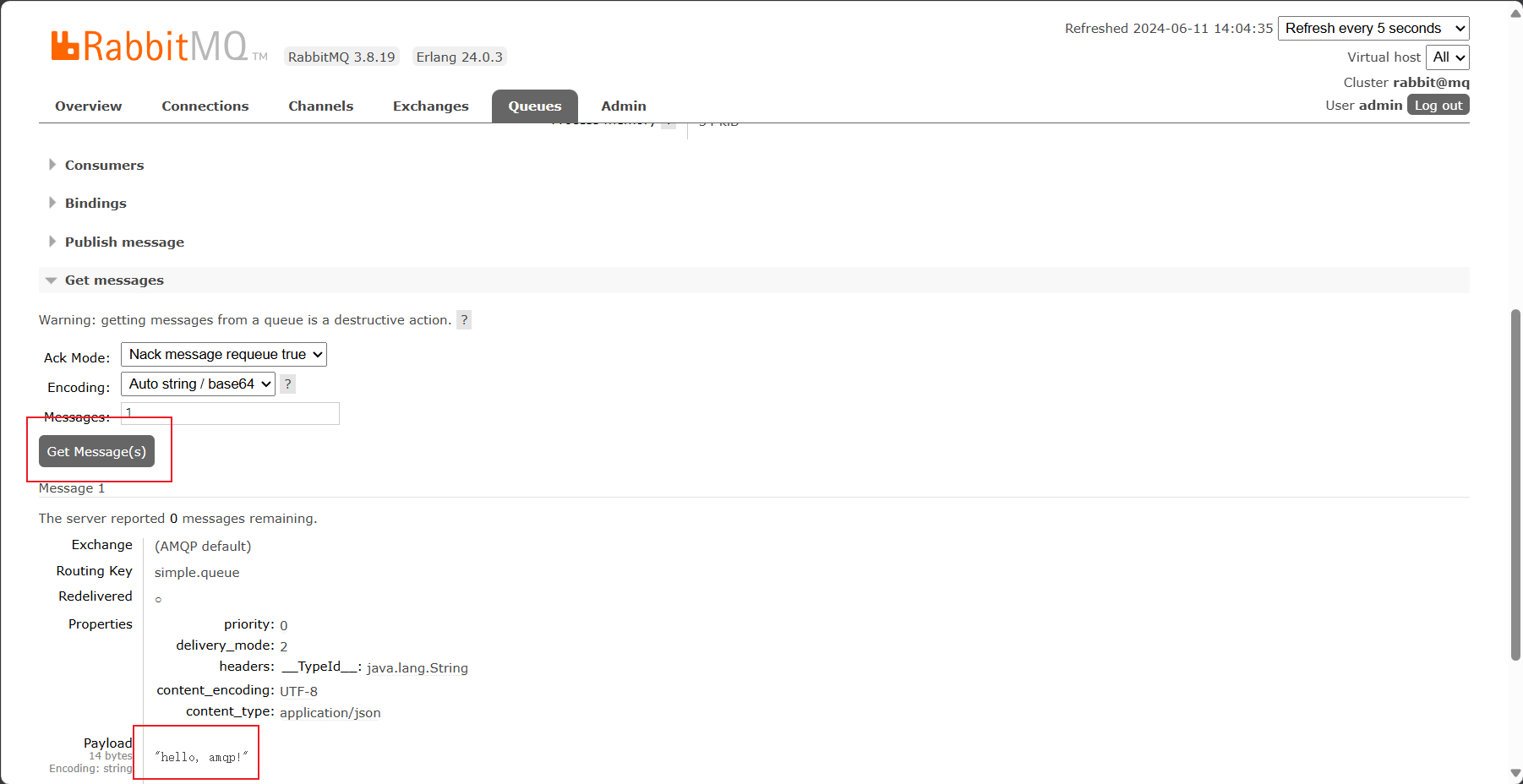
还可以获取到消息的详细信息
消费者
先编写消费者的配置信息
1 | |
编写消费类
1 | |
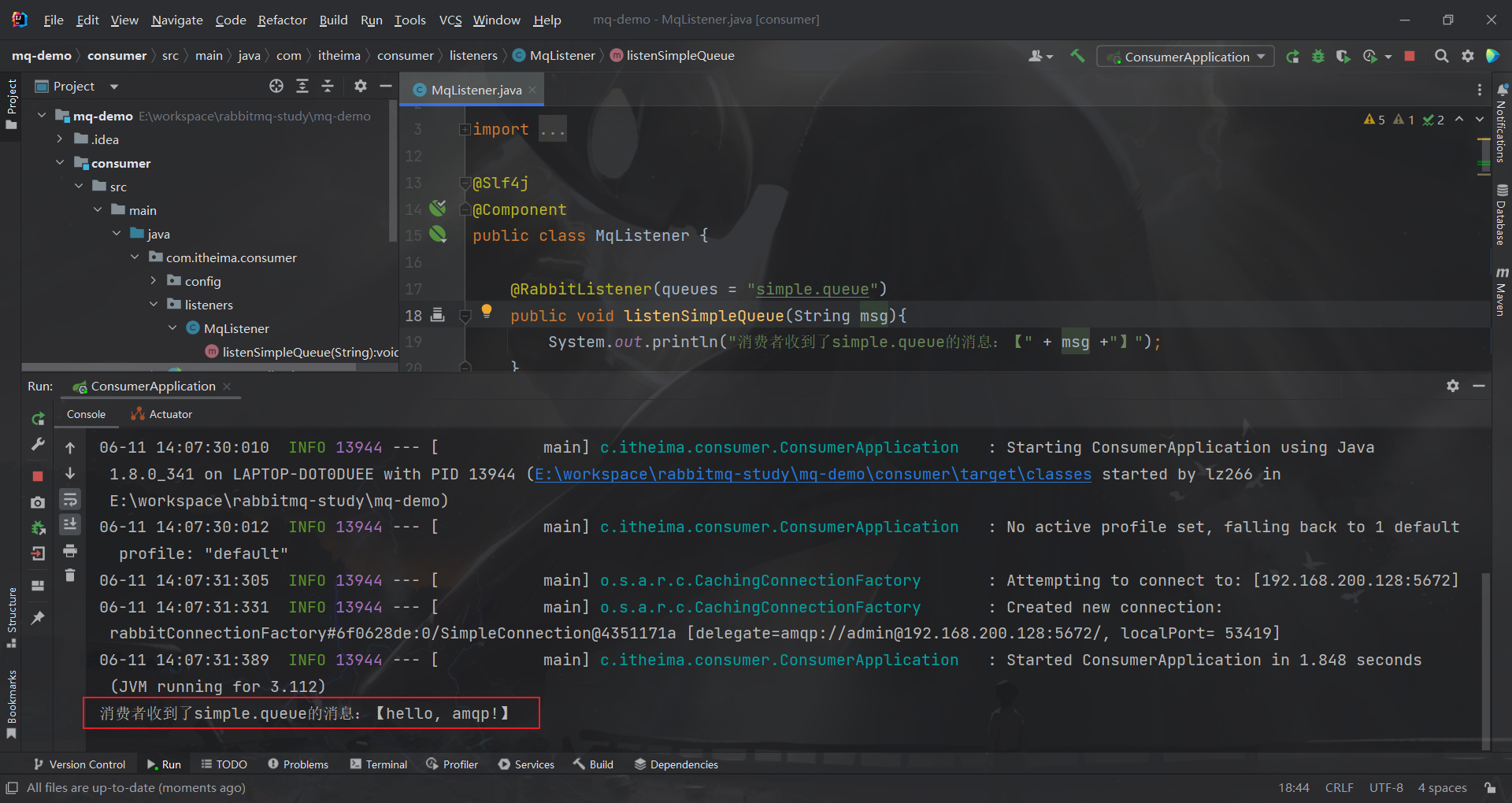
启动消费者模块,可以看到消息被获取到
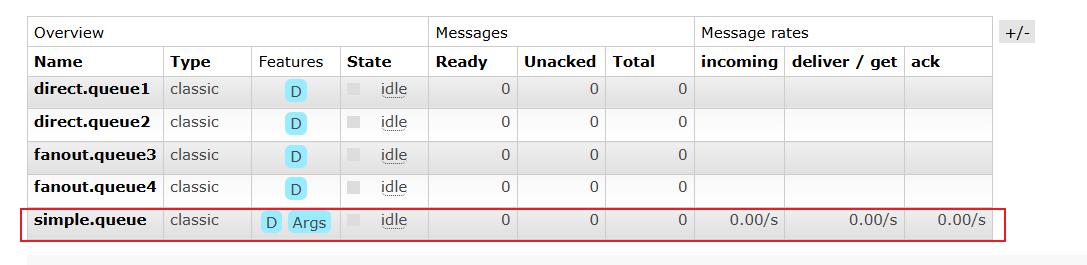
消息队列中的也不存在未消费的消息了
SpringAMQP如何收发消息
- 引入spring-boot-starter-amqp的依赖
- 配置rabbitmq服务端信息
- 利用RabbitTemplate发送消息
- 利用@RabbitListener注解声明要监听的队列,监听消息
4. work模型
Work queues,任务模型。简单来说就是让多个消费者绑定到一个队列,共同消费队列中的消息
案例:模仿WorkQueue,实现一个队列绑定多个消费者
实现思路:
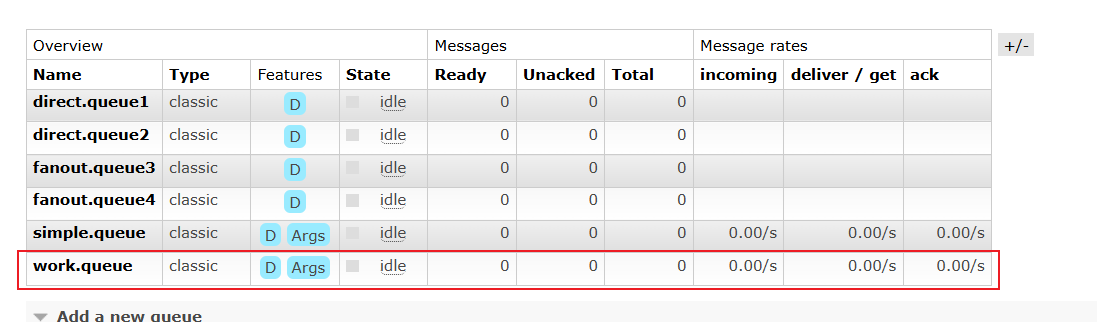
- 在RabbitMQ的控制台创建一个队列,名为work.queue
- 在publisher服务中定义测试方法,批量生成50条消息,发送到work.queue中
- 在consumer服务中定义两个消息监听者,都监听work.queue队列
- 模拟不同能力的消费者
- 消费者1和消费者2处理信息的能力一样
- 消费者1处理信息的能力是消费者2的10倍
- 通过给消费者增加延时来模仿不同消费者的能力
先在Web端控制台创建队列
创建测试方法,批量生成消息,发送到work.queue队列
1 | |
模拟第一种情况,两个消费者消费能力相同
创建两个消费者
1 | |
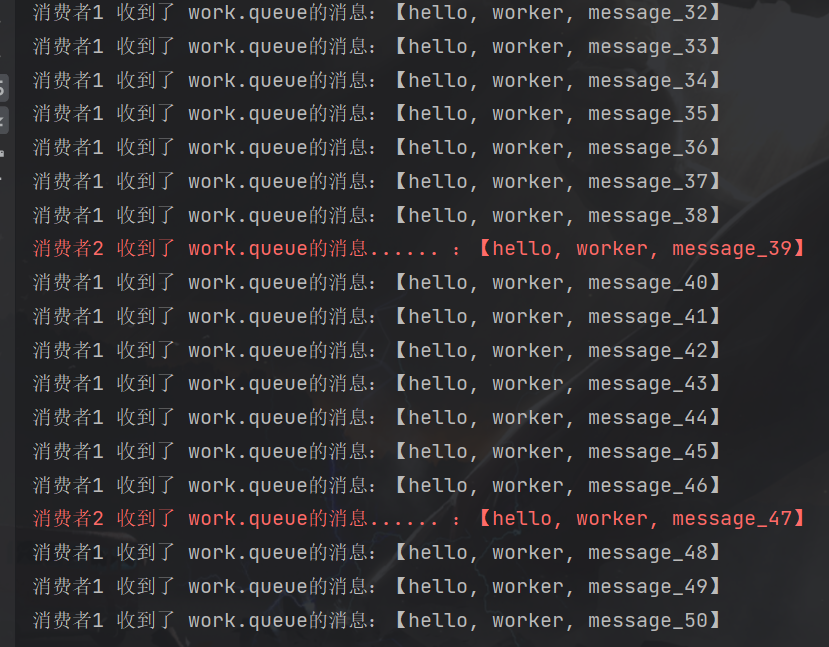
运行消费者模块,接收并消费消息
通过消费结果可以获得几个结论
- 多个消费者绑定到同一个队列时,队列中的一条消息只会被一个消费者消费,不会重复消费
- 这些消费者之间默认通过轮询的方式来消费这些消息
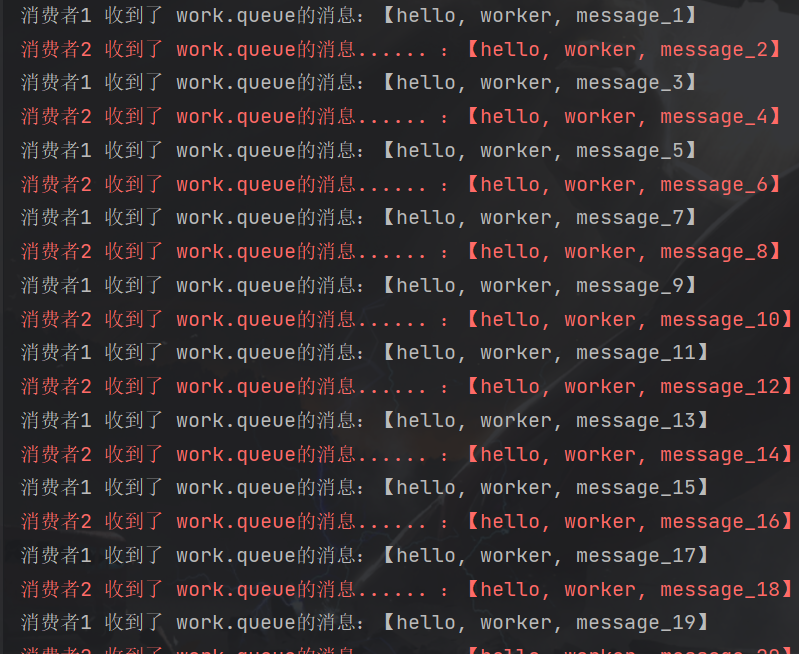
当消费者之间的性能相差过大时,这种轮询的方式就会出现弊端
模拟第二种情况,消费者1的能力是消费者2的10倍
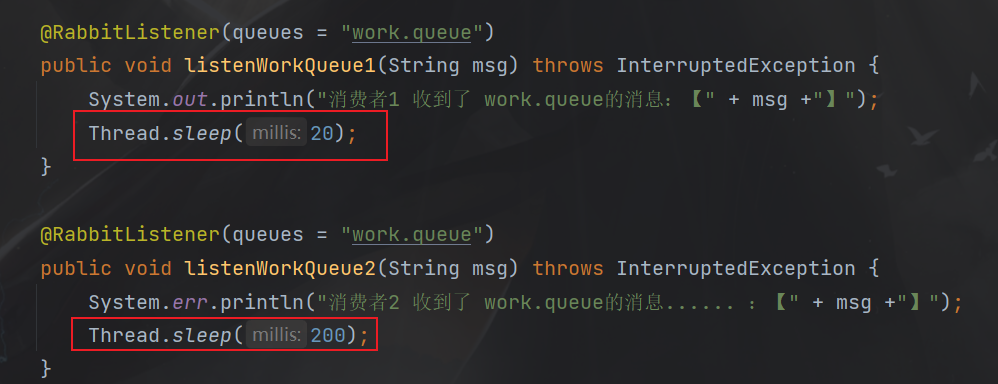
重启消费者模块,再次发送消息
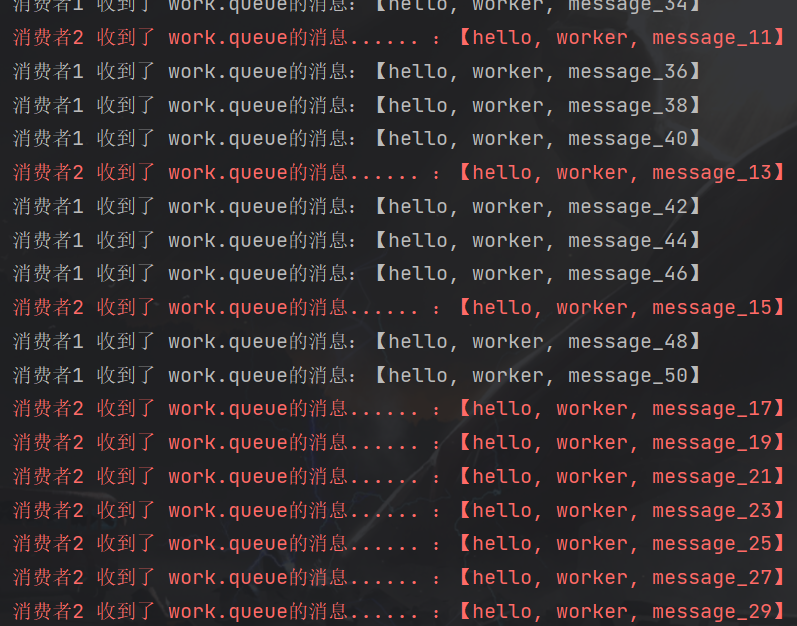
从测试结果可以看出,消费者1很快就消费了自己该消费的信息,而消费者2则大大的影响了整体速度,产生了消息堆积。所以在消费者的消费能力相差过大时,不能使用轮询的方式,可以通过更改配置文件,来指定一个消费者最多能同时消费消息的数量来解决这个问题
1 | |
更改完配置后再次测试,这样就解决了消息堆积的问题
Work模型的使用
- 多个消费者绑定到一个队列,可以加快消息处理速度
- 同一条消息只会被一个消费者处理
- 通过设置prefetch来控制消费者预取的消息数量,处理完一条消息再处理下一条
5. Fanout交换机
一般的消息都不是有生产者直接发送给队列的,而是生产者发送给交换机,交换机再转发到对应的队里中去
交换机有3种:Fanout广播,Direct定向,Topic话题
Fanout交换机也叫广播交换机,会将接收到的消息广播到每一个跟其绑定的queue
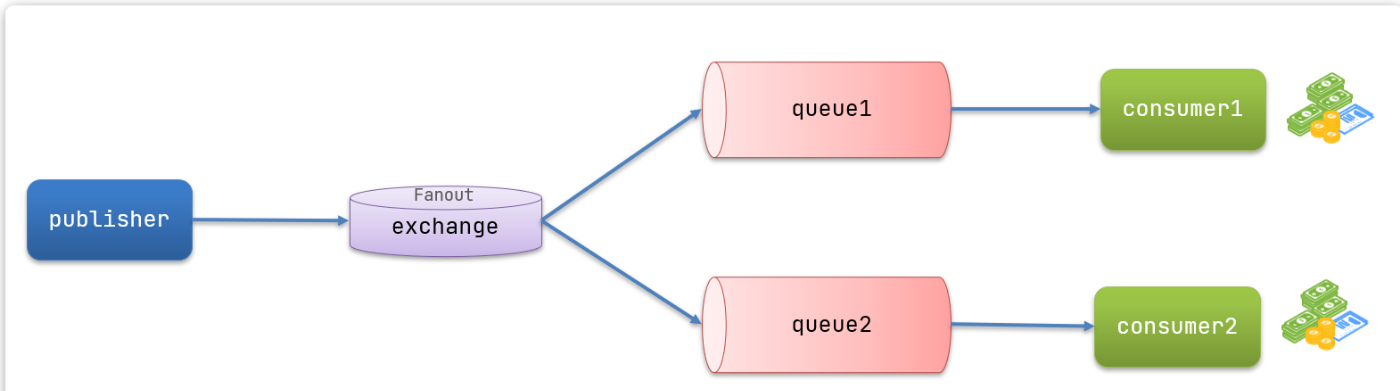
利用SpringAMQP演示FanoutExchange的使用
实现思路
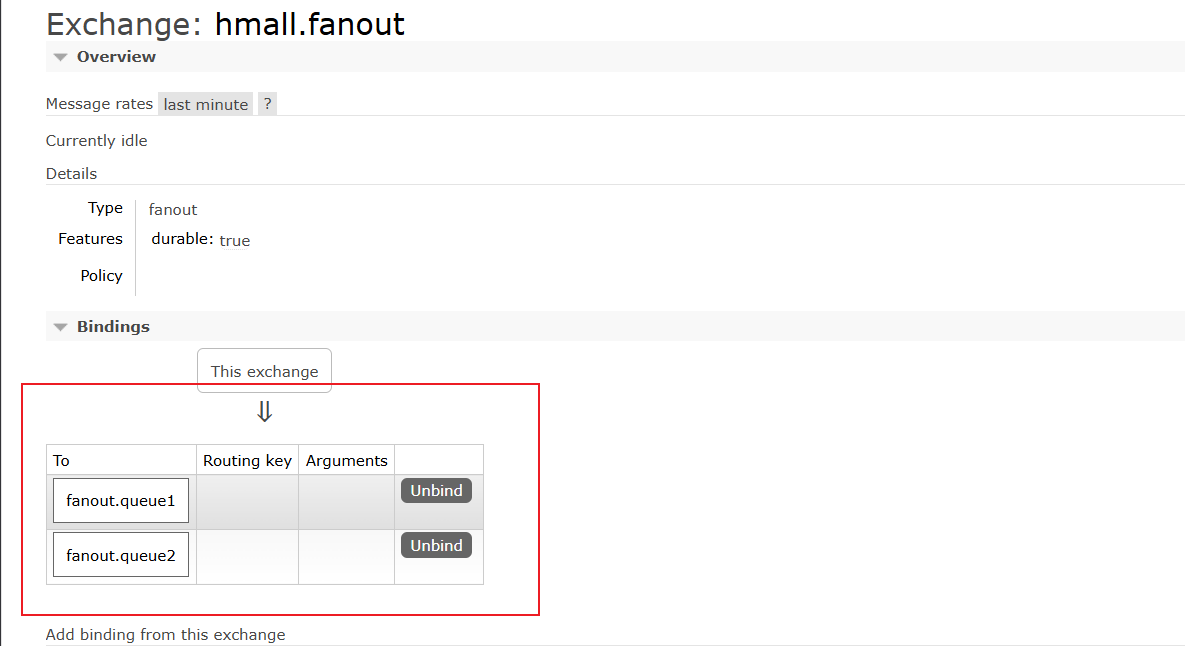
1. 在RabbitMQ控制台中,声明队列fanout.queue1和fanout.queue2
1. 在RabbitMQ控制台中,声明交换机hmall.fanout,同时绑定上面声明的两个队列
1. 在consumer服务中,编写两个消费者方法,分别监听队列1和队列2
1. 在publisher中编写测试方法,向交换机中发送消息
创建队列
创建交换机
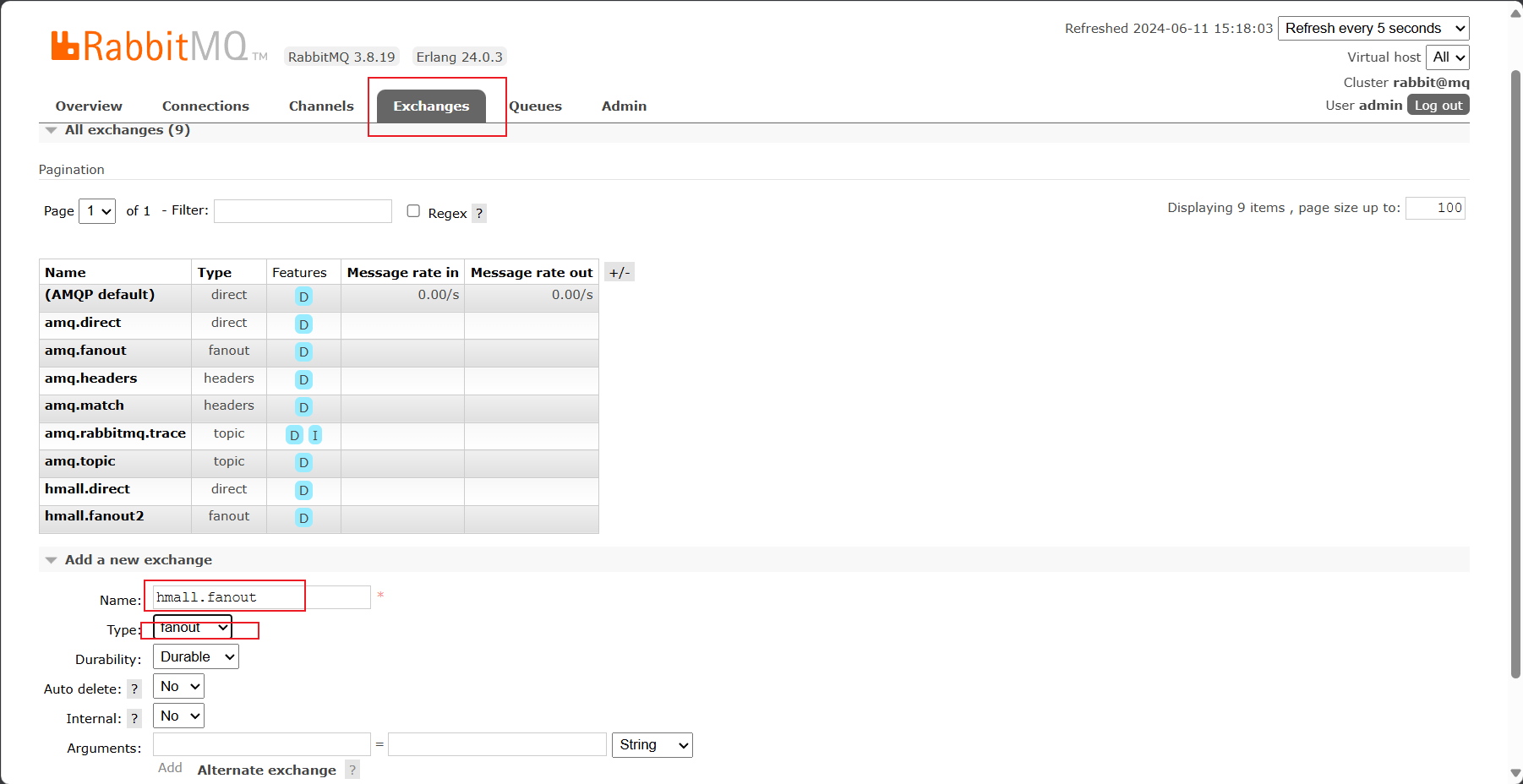
绑定交换机和队列
编写消费者
1 | |
编写生产者方法
1 | |
测试
从测试结果可以看出这两个消息队列都从交换机接收到了消息

总结
交换机的作用是什么?
- 接收publisher发送的消息
- 将消息按照规则路由到与之绑定的队列
- 不能缓存消息,路由失败,消息丢失
- FanoutExchange的会将消息路由到每个绑定的队列
6. Direct交换机
在Fanout模式中,一条消息,会被所有订阅的队列都消费。但是,在某些场景下,我们希望不同的消息被不同的队列消费。这时就要用到Direct类型的Exchange
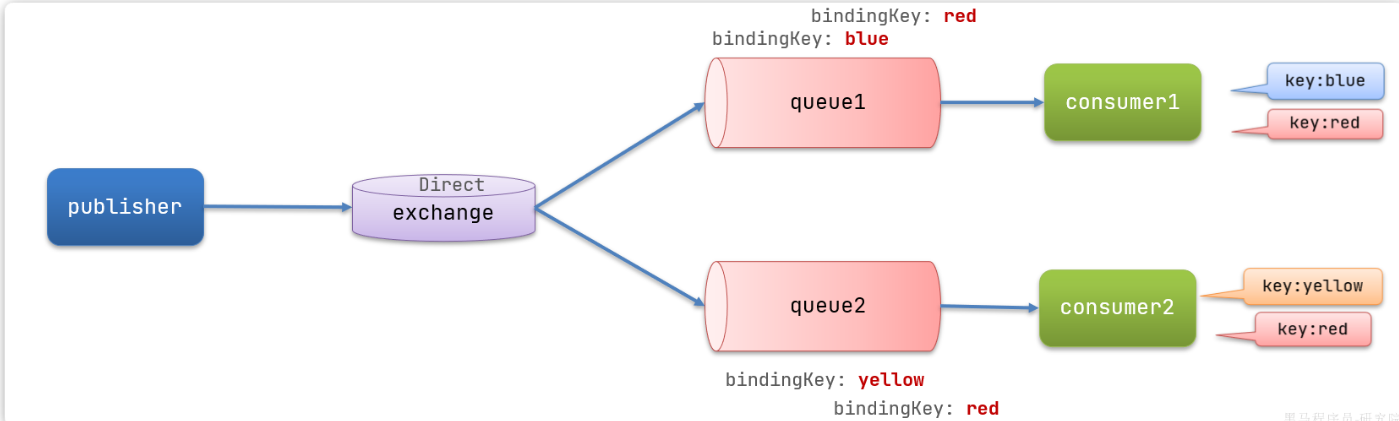
在Direct模型下:
- 队列与交换机的绑定,不能是任意绑定了,而是要指定一个
RoutingKey(路由key) - 消息的发送方在 向 Exchange发送消息时,也必须指定消息的
RoutingKey。 - Exchange不再把消息交给每一个绑定的队列,而是根据消息的
Routing Key进行判断,只有队列的Routingkey与消息的Routing key完全一致,才会接收到消息
案例:利用SpringAMQP演示DirectExchange的使用
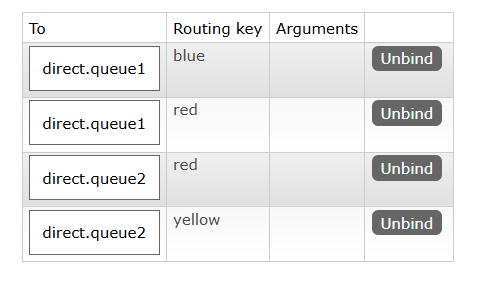
- 声明一个名为
hmall.direct的交换机 - 声明队列
direct.queue1,绑定hmall.direct,bindingKey为blud和red - 声明队列
direct.queue2,绑定hmall.direct,bindingKey为yellow和red - 在
consumer服务中,编写两个消费者方法,分别监听direct.queue1和direct.queue2 - 在publisher中编写测试方法,向
hmall.direct发送消息
创建队列
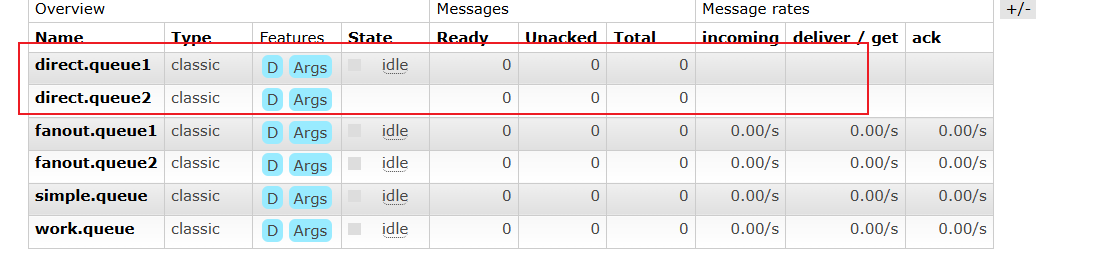
创建交换机
绑定交换机和队列
编写消费者
1 | |
编写生产者方法
1 | |
测试

Direct交换机与Fanout交换机的差异
- Fanout交换机将消息路由给每一个与之绑定的队列
- Direct交换机根据RoutingKey判断路由给哪个队列
- 如果多个队列具有相同的RoutingKey,则与Fanout功能类似
7. Topic交换机
Topic类型的Exchange与Direct相比,都是可以根据RoutingKey把消息路由到不同的队列。
只不过Topic类型Exchange可以让队列在绑定BindingKey 的时候使用通配符!
BindingKey 一般都是有一个或多个单词组成,多个单词之间以.分割,例如: item.insert
通配符规则:
#:匹配一个或多个词*:匹配不多不少恰好1个词
举例:
item.#:能够匹配item.spu.insert或者item.spuitem.*:只能匹配item.spu
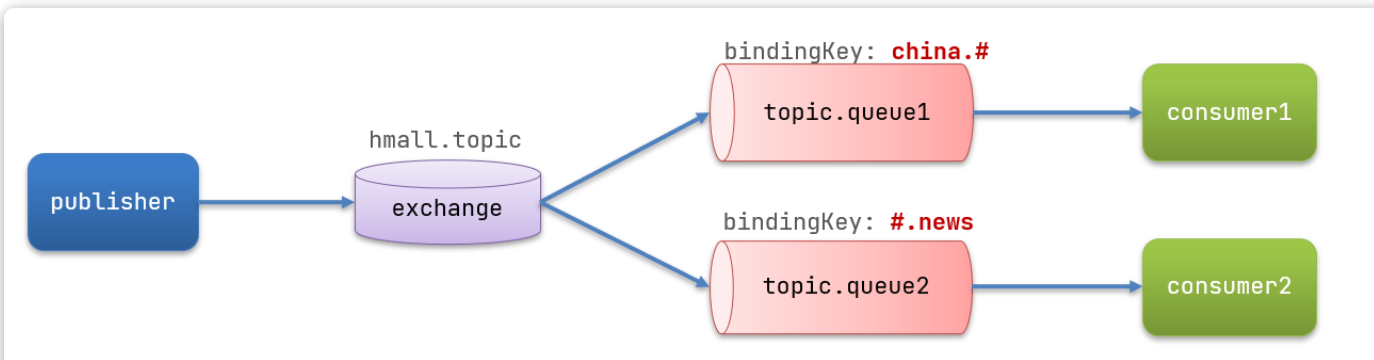
假如此时publisher发送的消息使用的RoutingKey共有四种:
china.news代表有中国的新闻消息;china.weather代表中国的天气消息;japan.news则代表日本新闻japan.weather代表日本的天气消息;
解释:
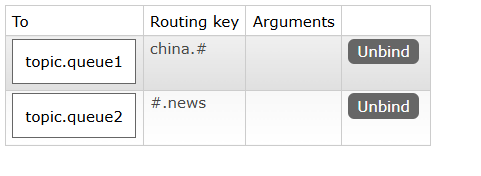
topic.queue1:绑定的是china.#,凡是以china.开头的routing key都会被匹配到,包括:china.newschina.weather
topic.queue2:绑定的是#.news,凡是以.news结尾的routing key都会被匹配。包括:china.newsjapan.news
案例:利用SpringAMQP演示DirectExchange的使用
需求:
- 在RabbitMQ控制台中,声明队列topic.queue1和topic.queue2
- 在RabbitMQ控制台中,声明交换机hmall.topic,将两个队列与其绑定
- 在consumer服务中,编写两个消费者方法,分别监听topic.queue1和topic.queue2
- 在publisher中编写测试方法,利用不同的RoutingKey向hmall.topic发送消息
创建队列
创建交换机
绑定交换机和队列
编写消费者
1 | |
编写生产者方法
1 | |
测试结果

Direct交换机与Topic交换机的差异
- Topic交换机接收的消息RoutingKey必须是多个单词,以
**.**分割 - Topic交换机与队列绑定时的bindingKey可以指定通配符
#:代表0个或多个词*:代表1个词
8. 声明队列和交换机
未完待续